第дёҖиҙўз»Ҹ
жқҺжҖЎ
2026-03-31 01:38:45


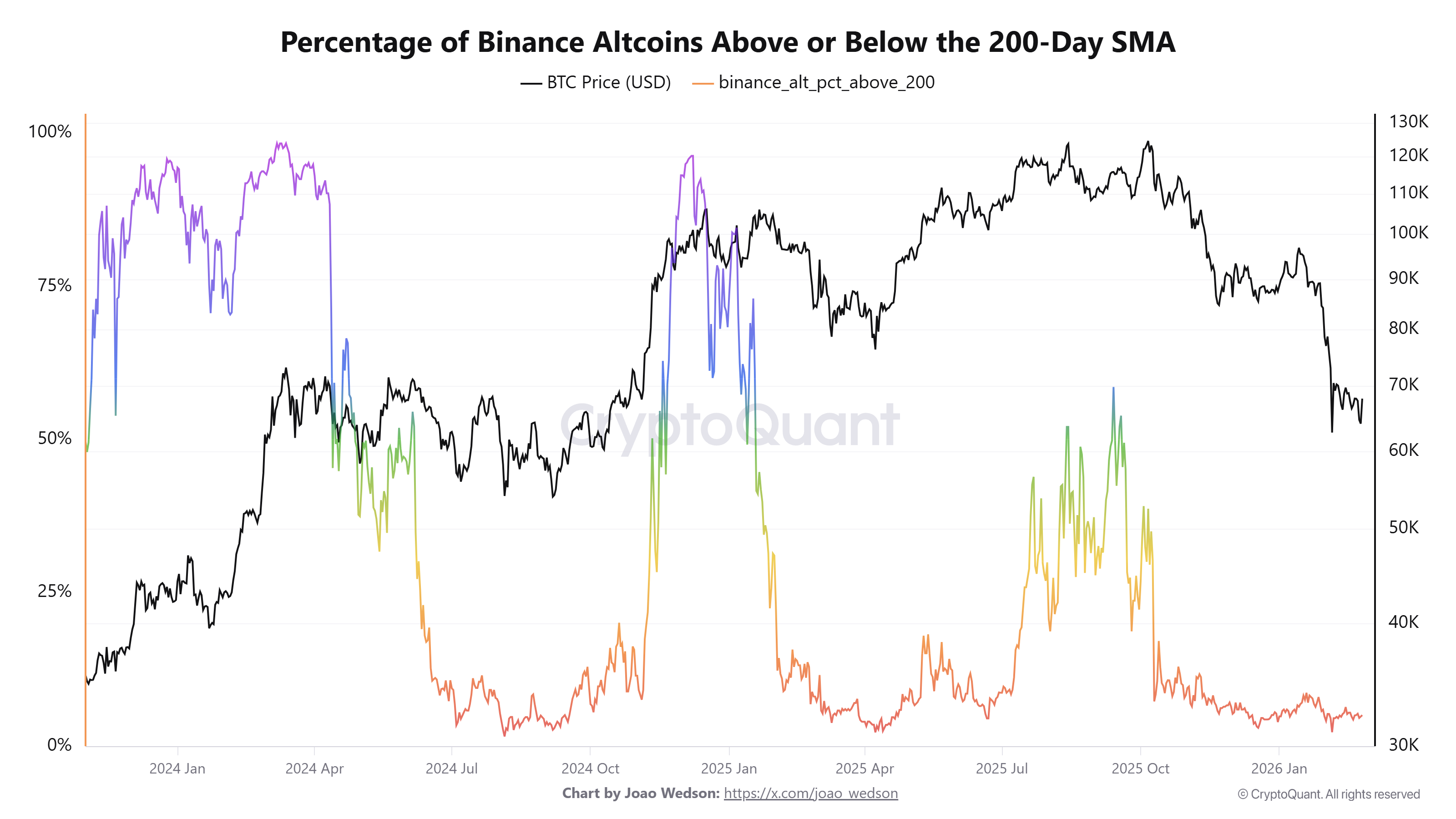
еңЁж•°жҚ®йў„еӨ„зҗҶе®ҢжҲҗеҗҺпјҢжҲ‘们еҸҜд»ҘдҪҝз”Ёеҗ„з§Қж•°жҚ®еҲҶжһҗе·Ҙе…·е’Ңз®—жі•жқҘжҺўзҙўж•°жҚ®дёӯзҡ„жЁЎејҸе’Ң规еҫӢгҖӮдҫӢеҰӮпјҢжҲ‘们еҸҜд»ҘдҪҝз”ЁиҜҚйў‘еҲҶжһҗжқҘдәҶи§ЈвҖңдё°е№ҙз»Ҹ继вҖҳжӢҮвҖҷвҖқеңЁдёҚеҗҢиҜӯеўғдёӯзҡ„дҪҝз”Ёйў‘зҺҮе’ҢеҲҶеёғгҖӮжҲ‘们иҝҳеҸҜд»ҘдҪҝз”Ёдё»йўҳжЁЎеһӢпјҲеҰӮLDAпјүжқҘиҜҶеҲ«дёҺиҝҷдёӘиҜҚиҜӯзӣёе…ізҡ„дё»иҰҒиҜқйўҳе’Ңи®Ёи®әж–№еҗ‘гҖӮ
жҲ‘们еҸҜд»ҘдҪҝз”Ёж—¶й—ҙеәҸеҲ—еҲҶжһҗжқҘз ”з©¶иҝҷдёӘиҜҚиҜӯзҡ„дҪҝз”Ёйў‘зҺҮйҡҸж—¶й—ҙзҡ„еҸҳеҢ–и¶ӢеҠҝгҖӮдҫӢеҰӮпјҢжҲ‘们еҸҜд»ҘеҲҶжһҗеңЁдёҚеҗҢзҡ„ж—¶й—ҙж®өеҶ…пјҢвҖңдё°е№ҙз»Ҹ继вҖҳжӢҮвҖҷвҖқжҳҜеҗҰжңүзү№е®ҡзҡ„й«ҳеі°жҲ–дҪҺи°·пјҢиҝҷеҸҜиғҪдјҡжҸӯзӨәеҮәе…¶дҪҝз”ЁиғҢеҗҺзҡ„规еҫӢгҖӮ
дёәдәҶе®һзҺ°вҖңдё°е№ҙз»Ҹ继вҖҳжӢҮвҖҷвҖқзҡ„зӣ®ж ҮпјҢж•ҷиӮІе’Ңдј жүҝд№ҹжҳҜйқһеёёйҮҚиҰҒзҡ„зҺҜиҠӮгҖӮжҲ‘们йңҖиҰҒйҖҡиҝҮж•ҷиӮІзі»з»ҹпјҢеҗ‘е№ҙиҪ»дёҖд»Јдј жҺҲиҝҷз§Қж–°еһӢзҡ„з»ҸжөҺз®ЎзҗҶе’ҢжҷәиғҪеҢ–з”ҹжҙ»ж–№ејҸгҖӮжҲ‘们иҝҳйңҖиҰҒйҖҡиҝҮ家еәӯеҶ…йғЁзҡ„дј жүҝрҹ“қпјҢи®©иҝҷз§Қжҷәж…§е’Ңз»ҸйӘҢд»Јд»ЈрҹҺҜзӣёдј пјҢдёәзӨҫдјҡзҡ„иҝӣжӯҘе’ҢеҸ‘еұ•еҒҡеҮәжӣҙеӨ§зҡ„иҙЎзҢ®гҖӮ
йҡҸзқҖзӨҫдјҡзҡ„рҹ”ҘиҝӣжӯҘе’Ң科жҠҖзҡ„еҸ‘еұ•пјҢдәә们еҜ№дәҺз”ҹжҙ»иҙЁйҮҸе’Ңз»ҸжөҺж•ҲзӣҠзҡ„иҰҒжұӮи¶ҠжқҘи¶Ҡй«ҳгҖӮеңЁиҝҷз§ҚиғҢжҷҜдёӢпјҢвҖңдё°е№ҙз»Ҹ继вҖҳжӢҮвҖҷвҖқзҡ„зҗҶеҝөпјҢдёәжҲ‘们жҸҗдҫӣдәҶдёҖжқЎе…Ёж–°зҡ„йҒ“и·ҜгҖӮйҖҡиҝҮиҝҷжқЎйҒ“и·ҜпјҢжҲ‘们дёҚд»…еҸҜд»Ҙе®һзҺ°е®¶еәӯз»ҸжөҺзҡ„жҢҒз»ӯеҸ‘еұ•пјҢиҝҳиғҪдёәзӨҫдјҡзҡ„иҝӣжӯҘе’Ңз№ҒиҚЈеҒҡеҮәз§ҜжһҒзҡ„иҙЎзҢ®гҖӮ
еҰӮжһңд»…д»…жҳҜйҡҸжңәзҡ„еӯ—з¬Ұз»„еҗҲпјҢйӮЈд№Ҳе®ғзҡ„еҮәзҺ°е°ұеҰӮеҗҢдёҖзүҮиў«йЈҺеҗ№ж•Јзҡ„ж ‘еҸ¶пјҢжІЎжңүж–№еҗ‘пјҢжІЎжңүзӣ®зҡ„гҖӮ
дә’иҒ”зҪ‘зҡ„йӯ…еҠӣжҒ°жҒ°еңЁдәҺе®ғиғҪеӨҹе°ҶиҝҷдәӣзңӢдјјеҒ¶з„¶зҡ„зўҺзүҮиҝһжҺҘиө·жқҘпјҢиөӢдәҲе®ғ们新зҡ„з”ҹе‘ҪгҖӮеңЁзӨҫдәӨеӘ’дҪ“гҖҒи®әеқӣгҖҒжёёжҲҸзӨҫзҫӨдёӯпјҢжҖ»жңүдёҖзҫӨдәәзғӯиЎ·дәҺжҢ–жҺҳе’Ңи§ЈиҜ»иҝҷдәӣвҖңйҡҗз§ҳвҖқзҡ„дҝЎжҒҜгҖӮ他们дјҡд»ҺиҜҚиҜӯзҡ„жһ„жҲҗгҖҒеҸ‘йҹігҖҒз”ҡиҮіеӯ—еҪўдёҠеҜ»жүҫиӣӣдёқ马иҝ№гҖӮдҫӢеҰӮпјҢвҖңдё°е№ҙвҖқжҲ–и®ёиғҪи®©дәәиҒ”жғіеҲ°дё°ж”¶гҖҒеҜҢи¶ігҖҒеҗүзҘҘзҡ„еҜ“ж„ҸпјӣвҖңз»Ҹ继вҖқеҲҷеёҰжңүдј жүҝгҖҒ延з»ӯгҖҒеҸ‘еұ•зҡ„ж„Ҹе‘іпјӣиҖҢйӮЈдёӘеӯӨйӣ¶йӣ¶зҡ„вҖңжӢҮвҖқпјҢжӣҙжҳҜи®©дәәжҚүж‘ёдёҚйҖҸгҖӮ
жҳҜвҖңжӢҮжҢҮвҖқзҡ„з®Җз§°пјҹжҠ‘жҲ–жҳҜжҹҗз§ҚжӣҙдёәеҸӨиҖҒгҖҒжӣҙе°‘и§Ғзҡ„жұүеӯ—пјҹ
жңүдәәеҸҜиғҪдјҡе°қиҜ•е°ҶвҖңдё°е№ҙз»Ҹ继вҖҳжӢҮвҖҷвҖқжӢҶи§ЈжҲҗдёҚеҗҢзҡ„йғЁеҲҶиҝӣиЎҢжҗңзҙўгҖӮеңЁжҗңзҙўеј•ж“Һдёӯиҫ“е…ҘвҖңдё°е№ҙз»Ҹ继вҖқпјҢд№ҹи®ёиғҪжүҫеҲ°дёҖдәӣе…ідәҺеҶңдёҡгҖҒз»ҸжөҺгҖҒжҲ–иҖ…家ж—Ҹдј жүҝзҡ„йӣ¶ж•ЈдҝЎжҒҜгҖӮдҪҶеҪ“еҠ е…ҘвҖңжӢҮвҖқеӯ—д№ӢеҗҺпјҢжҗңзҙўз»“жһңеҫҖеҫҖеҸҳеҫ—жӣҙеҠ жү‘жң”иҝ·зҰ»гҖӮе®ғеҸҜиғҪжҢҮеҗ‘дёҖдәӣжһҒдёәе°Ҹдј—зҡ„и®әеқӣеё–еӯҗпјҢдёҖдәӣжёёжҲҸзҺ©е®¶зҡ„и®Ёи®әпјҢз”ҡиҮіжҳҜдёҖдәӣеҸӨзұҚзҡ„зүҮж®өгҖӮ
зҪ‘з»ңдј иҫ“иҝҮзЁӢдёӯзҡ„д№ұз Ғй—®йўҳд№ҹжҳҜеёёи§Ғзҡ„жҠҖжңҜжҢ‘жҲҳгҖӮзҪ‘з»ңдј иҫ“дёӯзҡ„ж•°жҚ®еҸҜиғҪдјҡеҸ—еҲ°е№Іжү°жҲ–дёўеӨұпјҢеҜјиҮҙж•°жҚ®еҢ…йҮҚз»„й”ҷиҜҜпјҢд»ҺиҖҢеҮәзҺ°д№ұз ҒгҖӮдёәдәҶйҒҝе…Қиҝҷз§Қжғ…еҶөпјҢеҸҜд»ҘйҮҮеҸ–д»ҘдёӢжҺӘвӯҗж–Ҫпјҡ
зЁіе®ҡзҡ„зҪ‘з»ңиҝһжҺҘпјҡзЎ®дҝқзҪ‘з»ңиҝһжҺҘзҡ„зЁіе®ҡжҖ§пјҢеҮҸе°‘зҪ‘з»ңдёӯж–ӯе’Ңж•°жҚ®еҢ…пҝҪз»ӯпјҡ
ж•°жҚ®еҺӢзј©дёҺдј иҫ“пјҡеңЁзҪ‘з»ңдј иҫ“дёӯпјҢеҸҜд»ҘдҪҝз”Ёж•°жҚ®еҺӢзј©жҠҖжңҜжқҘеҮҸе°‘ж•°жҚ®дј иҫ“зҡ„йҮҸпјҢдҪҶйңҖиҰҒжіЁж„ҸеҺӢзј©дёҺи§ЈеҺӢзј©иҝҮзЁӢдёӯзҡ„зј–з Ғж јејҸдёҖиҮҙжҖ§пјҢд»ҘйҒҝе…Қд№ұз Ғй—®йўҳгҖӮ
дј иҫ“еҚҸи®®зҡ„йҖүжӢ©пјҡйҖүжӢ©зЁіе®ҡгҖҒеҸҜйқ зҡ„дј иҫ“еҚҸи®®пјҢеҰӮHTTPSжҲ–FTPпјҢеҸҜд»Ҙжңүж•ҲеҮҸе°‘ж•°жҚ®дј иҫ“дёӯзҡ„д№ұз Ғй—®йўҳгҖӮ
дёәдәҶжӣҙеҘҪең°зҗҶи§ЈвҖңдё°е№ҙз»Ҹ继вҖңжӢҮвҖқжҳҜд№ұз ҒиҝҳжҳҜеӣҪзІҫ?вҖқиҝҷдёҖй—®йўҳпјҢжҲ‘们йңҖиҰҒд»ҺжҠҖжңҜеұӮйқўиҝӣиЎҢеҲҶжһҗгҖӮжҲ‘们йңҖиҰҒзЎ®и®ӨиҝҷдёӘеӯ—з¬Ұзҡ„жӯЈзЎ®зј–з Ғж јејҸгҖӮеңЁдёӯж–ҮдҝЎжҒҜеӨ„зҗҶдёӯпјҢеёёз”Ёзҡ„зј–з Ғж јејҸжңүGB2312гҖҒGBKгҖҒUTF-8зӯүгҖӮдёҚеҗҢзҡ„зј–з Ғж јејҸеҜ№еӯ—з¬Ұзҡ„и§Јз Ғж–№ејҸдёҚеҗҢпјҢд»ҺиҖҢеҸҜиғҪеҜјрҹ“қиҮҙд№ұз Ғзҡ„дә§з”ҹгҖӮ
и®©жҲ‘们жқҘдәҶи§ЈдёҖдёӢд»Җд№ҲжҳҜвҖңд№ұз ҒвҖқгҖӮеңЁи®Ўз®—жңәе’ҢзҪ‘з»ңдё–з•ҢдёӯпјҢд№ұз ҒйҖҡеёёжҳҜжҢҮз”ұдәҺзј–з ҒдёҚдёҖиҮҙжҲ–дј иҫ“й”ҷиҜҜиҖҢдә§з”ҹзҡ„дёҚеҸҜзҗҶи§Јзҡ„еӯ—з¬ҰгҖӮиҝҷдәӣд№ұз ҒеҸҜиғҪдјҡеҮәзҺ°еңЁз”өеӯҗйӮ®д»¶гҖҒзҪ‘йЎөгҖҒиҪҜ件жҳҫзӨәзӯүеҗ„дёӘж–№йқўгҖӮеңЁдёӯеӣҪпјҢд№ұз Ғй—®йўҳе°Өе…¶еёёи§ҒпјҢеӣ дёәжұүеӯ—зҡ„зј–з ҒеӨҚжқӮпјҢеӨҡз§Қзј–з Ғж јејҸпјҲеҰӮGB2312гҖҒGBKгҖҒUTF-8зӯүпјүзҡ„дәӨеҸүдҪҝз”ЁпјҢеёёеёёеҜјиҮҙд№ұз Ғзҡ„дә§з”ҹгҖӮ
еңЁеҸӨд»ЈпјҢжӢҮжҢҮзҡ„еҠӣйҮҸе’ҢжҺ§еҲ¶иғҪеҠӣеҫҖеҫҖиў«и§Ҷдёәжҹҗз§Қжҷәж…§е’ҢжҠҖиғҪзҡ„рҹ”ҘиұЎеҫҒгҖӮдҫӢеҰӮпјҢеңЁжҹҗдәӣжүӢе·ҘиүәжңҜдёӯпјҢжӢҮжҢҮзҡ„зҒөе·§е’ҢеҠӣйҮҸжҳҜеҲ¶дҪңзІҫзҫҺдҪңе“Ғзҡ„е…ій”®гҖӮеӣ жӯӨпјҢеҪ“жҲ‘们и°Ҳи®әвҖңдё°е№ҙз»Ҹ继вҖҳжӢҮвҖҷвҖқж—¶пјҢеҸҜиғҪжҳҜеңЁејәи°ғдёҖз§ҚжҠҖиғҪжҲ–жҷәж…§зҡ„дј жүҝрҹ“қгҖӮ
еңЁзҺ°д»ЈрҹҺҜзӨҫдјҡпјҢж–ҮеҢ–дј жүҝдёҺжҠҖжңҜеҸ‘еұ•жҳҜзҙ§еҜҶзӣёиҝһзҡ„гҖӮжҲ‘们еҸҜд»ҘйҖҡиҝҮзҺ°д»ЈжҠҖжңҜжүӢж®өпјҢжҜ”еҰӮж•°еӯ—еҢ–е’ҢзҪ‘з»ңдј ж’ӯпјҢжқҘдҝқжҠӨе’Ңдј жүҝйӮЈдәӣзҸҚиҙөзҡ„ж–ҮеҢ–йҒ—дә§гҖӮиҝҷдёҚд»…иғҪеӨҹи®©жӣҙеӨҡзҡ„дәәдәҶи§Јиҝҷдәӣж–ҮеҢ–пјҢиҝҳиғҪеӨҹи®©е®ғ们еңЁж–°зҡ„рҹ”Ҙж—¶д»ЈрҹҺҜдёӯз„•еҸ‘ж–°зҡ„з”ҹе‘ҪеҠӣгҖӮ
иҰҒзҗҶи§Јдёәд»Җд№ҲдјҡеҮәзҺ°д№ұз ҒпјҢжҲ‘们йңҖиҰҒж·ұе…ҘдәҶи§Ји®Ўз®—жңәзҡ„зј–з Ғзі»з»ҹгҖӮи®Ўз®—жңәйҖҡиҝҮдәҢиҝӣеҲ¶зі»з»ҹжқҘеӨ„зҗҶж•°жҚ®пјҢиҖҢдёҚеҗҢзҡ„зј–з Ғзі»з»ҹдјҡз”ЁдёҚеҗҢзҡ„дәҢиҝӣеҲ¶еәҸеҲ—жқҘиЎЁзӨәеҗҢдёҖдёӘеӯ—з¬ҰгҖӮеёёи§Ғзҡ„зј–з Ғзі»з»ҹжңүUTF-8гҖҒGBKзӯүгҖӮеҪ“жҲ‘们еңЁдёҚеҗҢзҡ„зј–з Ғзі»з»ҹд№Ӣй—ҙиҝӣиЎҢж•°жҚ®дј иҫ“жҲ–жҳҫзӨәж—¶пјҢеҰӮжһңжІЎжңүжӯЈзЎ®иҪ¬жҚўзј–з Ғж јејҸпјҢе°ұеҸҜиғҪеҮәзҺ°д№ұз ҒгҖӮ
дҫӢеҰӮпјҢеңЁдёҖдёӘUTF-8зј–з Ғзҡ„зҪ‘йЎөдёӯпјҢеҰӮжһңжҸ’е…ҘдәҶGBKзј–з Ғзҡ„ж•°жҚ®пјҢжөҸи§ҲеҷЁеҸҜиғҪдјҡе°Ҷиҝҷдәӣж•°жҚ®и§ЈйҮҠжҲҗд№ұз ҒгҖӮеӣ жӯӨпјҢзј–з Ғй—®йўҳжҳҜеҜјиҮҙвҖңдё°е№ҙз»Ҹ继вҖҳжӢҮвҖҷвҖқжҳҫзӨәдёәд№ұз Ғзҡ„дёҖдёӘдё»иҰҒеҺҹеӣ гҖӮ
жңүдәәи®ӨдёәвҖңдё°е№ҙз»Ҹ继вҖҳжӢҮвҖҷвҖқжҳҜз”ұдәҺзј–з Ғй—®йўҳдә§з”ҹзҡ„д№ұз ҒгҖӮиҝҷз§Қи§ӮзӮ№зҡ„дҫқжҚ®жҳҜпјҢеҪ“рҹҷӮжҲ‘们иҫ“е…Ҙиҝҷдәӣеӯ—з¬Ұж—¶пјҢеҰӮжһңзј–з Ғж јејҸдёҚжӯЈзЎ®пјҢеҸҜиғҪдјҡжҳҫзӨәжҲҗд№ұз ҒгҖӮиҝҷз§Қжғ…еҶөйҖҡеёёеңЁзҪ‘йЎөжҳҫзӨәжҲ–з”өеӯҗйӮ®д»¶дј иҫ“дёӯжҜ”иҫғеёёи§ҒгҖӮдҫӢеҰӮпјҢеҰӮжһңдёҖдёӘзҪ‘йЎөдҪҝз”ЁдәҶдёҚж”ҜжҢҒжҹҗдәӣеӯ—з¬Ұзҡ„зј–з Ғж јејҸпјҢйӮЈд№Ҳиҝҷдәӣеӯ—з¬ҰеҸҜиғҪдјҡиў«й”ҷиҜҜжҳҫзӨәдёәд№ұз ҒгҖӮ
вҖңжӢҮвҖқжҳҜдёҖдёӘжұүеӯ—пјҢеңЁжұүеӯ—зј–з ҒдёӯеҚ жңүдёҖеёӯд№Ӣең°гҖӮе…¶дёӯпјҢжңҖеёёи§Ғзҡ„зј–з ҒжҳҜUTF-8пјҢе®ғжҳҜзӣ®еүҚдё–з•ҢдёҠжңҖе№ҝжіӣдҪҝз”Ёзҡ„еӯ—з¬Ұзј–з Ғж ҮеҮҶгҖӮеҰӮжһңвҖңжӢҮвҖқеңЁUTF-8зј–з ҒдёӢжҳҫзӨәжӯЈеёёпјҢйӮЈд№Ҳе®ғдёҚеұһдәҺд№ұз Ғзҡ„иҢғз•ҙгҖӮеңЁжҹҗдәӣзү№е®ҡзҡ„ж–ҮеҢ–жҲ–иҖ…дё“дёҡиғҢжҷҜдёӯпјҢвҖңжӢҮвҖқеҸҜиғҪдјҡжңүзү№ж®Ҡзҡ„еҗ«д№үпјҢиҝҷд№ҹиҝӣдёҖжӯҘеўһеҠ дәҶе®ғзҡ„зҘһз§ҳж„ҹгҖӮ